

第四章:CenterPoint模型训练与部署
点云目标检测介绍
点云目标检测算法是指输入为原始点云,输出为场景中目标的算法,如下图所示。

目前主流的点云目标检测分为3个方向:
原理 | 图示 | 代表论文 | 是否适合自动驾驶场景 | |
Point based |
|  |
| ❌ |
voxel based |
| 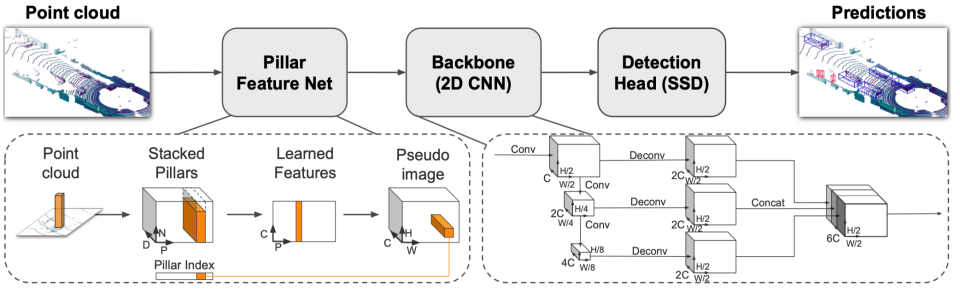 |
| ☑️ |
point-voxel based |
| 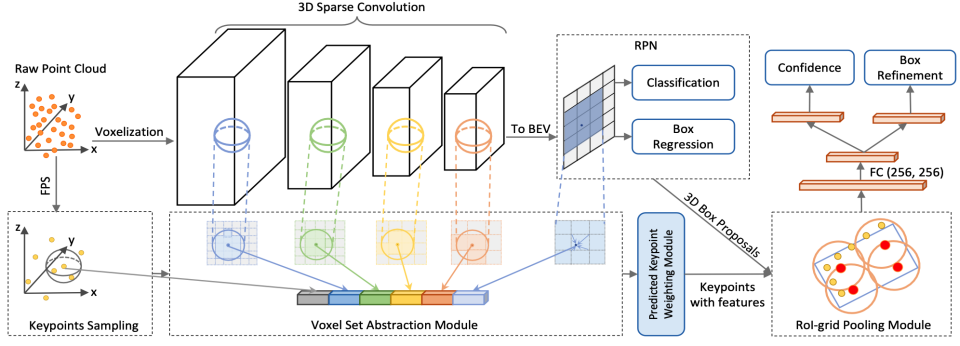 |
| ❌ |
目前Apollo中有4个lidar检测模型:
框架 | 原理 | |
CNNSeg | caffe |
|
PointPillars | torch |
|
MaskPillars | torch |
|
CenterPoint | paddle |
|
在使用过程中,用户在以下情况时需要自主训练并部署新的模型:
- 修改超参数 / 网络结构以提升3d检测效果
- 使用新的数据集训练模型,以提升对于某些特定类别的3d检测效果
目前Apollo推荐用户使用CenterPoint模型(paddlepaddle),用户可以使用Paddle3D开源代码库,快速方便地对centerpoint模型进行训练。本节课内容将分为以下几个部分,使用户能够自主训练lidar模型,并部署到apollo中进行检测。
- CenterPoint模型原理介绍
- Paddle3D训练CenterPoint
- 导出CenterPoint并在Apollo中部署
一、CenterPoint模型介绍
1.原理介绍
centerpoint论文链接:Center-based 3D Object Detection and Tracking
CenterPoint是Anchor-Free的三维物体检测器,以点云作为输入,将三维物体在Bird-View下的中心点作为关键点,基于关键点检测的方式回归物体的尺寸、方向和速度。相比于Anchor-Based的三维物体检测器,CenterPoint不需要人为设定Anchor尺寸,面向物体尺寸多样不一的场景时其精度表现更高,且简易的模型设计使其在性能上也表现更加高效。
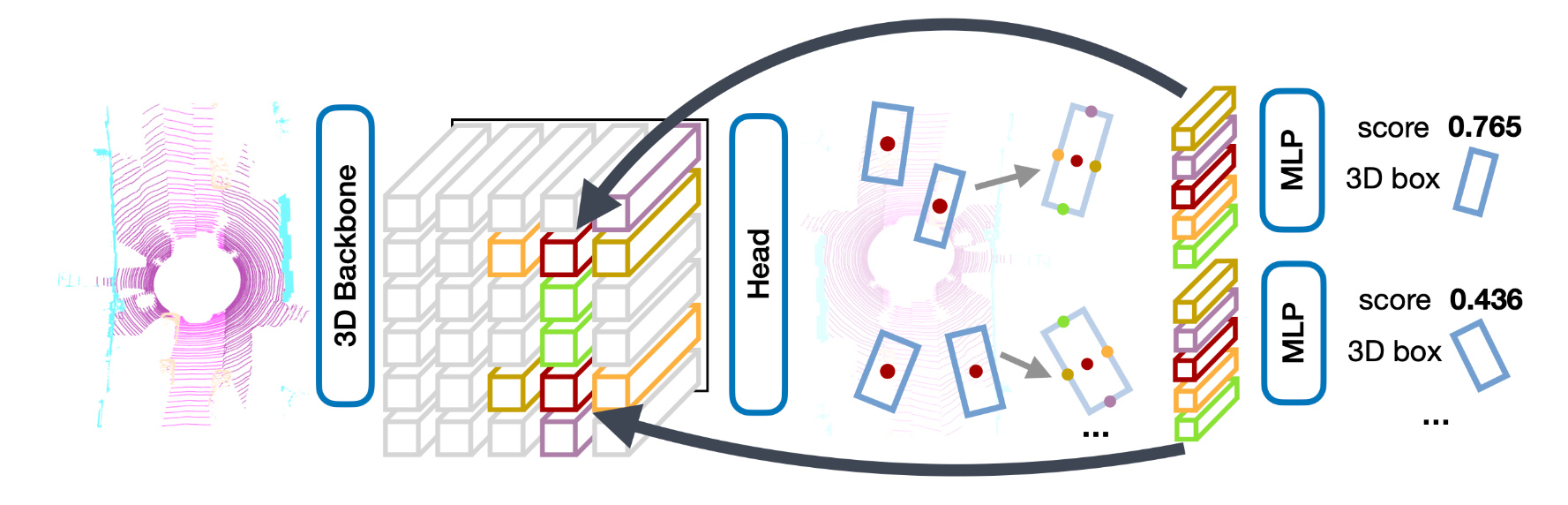
算法整体流程如下所示:
- 首先对输入的点云进行体素化(voxelization),也即将点云投影到pillar或者voxels中
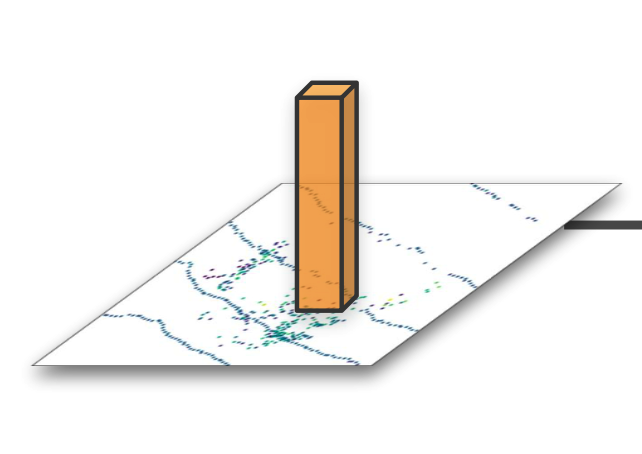
- 随后使用fully connection layer / 3d sparse convolution 提取pillar / voxels中的特征
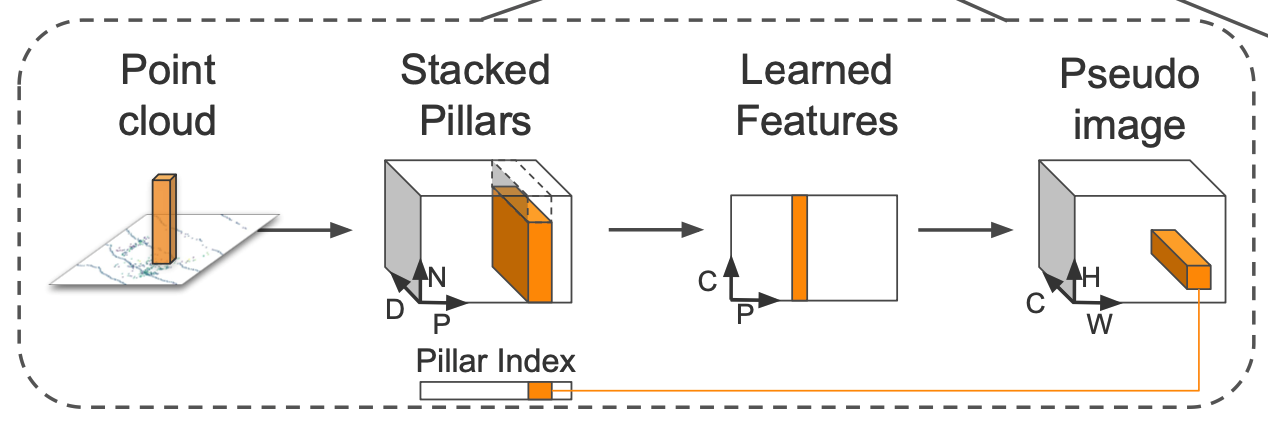
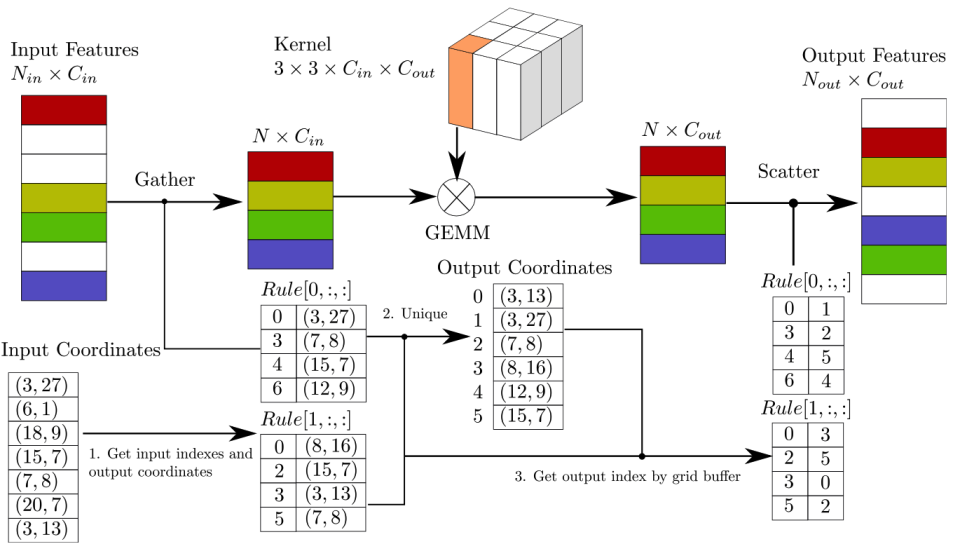
- 使用max pooling操作将pillar / voxels的特征“压缩”到BEV平面,获得BEV特征图
- 使用Second Backbone和Second Neck提取BEV的特征
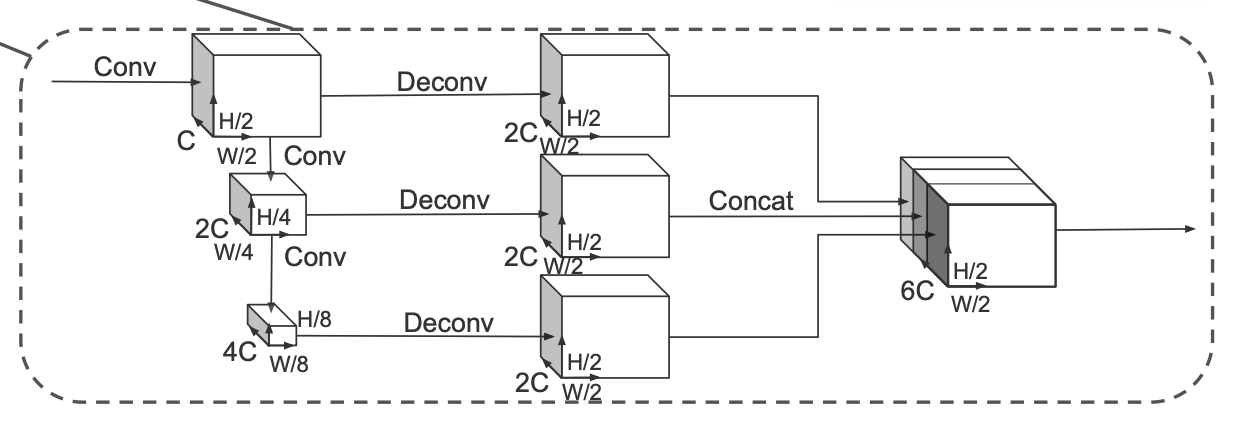
- head部分:
- 采用anchor-free的预测方式,直接预测目标的center位置
- 每个不同的类别使用不同head进行预测
- 预测内容包括:
- 目标中心位置 heatmap
- 目标中心和所在像素左上角的偏移量 offset
- 目标的长宽高 dim
- 目标center在激光雷达坐标系中的高度坐标 z
- 目标在激光雷达坐标系中的旋转角 rot


- 模型训练:
- heatmap训练使用Guassian Focal Loss
- 其他参数的训练使用Smooth L1 Loss
2.Apollo实现
apollo使用开源框架Paddle3D训练centerpoint模型,和原论文相比包括如下差异:
- 对模型的前后处理做了性能优化。CenterPoint-Pillars在nuScenesval set上精度有50.97mAP,速度在Tesla V100上达到了50.28FPS。
- 提供KITTI数据集上的训练配置和Baseline。CenterPoint-Pillars在KITTI val set上精度达到64.75 mAP,速度在Tesla V100上达到了43.96FPS。
- 未提供第二个阶段的实现。在原论文中,作者还设计了第二个阶段来进一步精炼物体的位置、尺寸和方向,并在Waymo数据集上做了验证。Paddle3D目前还未适配Waymo数据集,所以第二个阶段暂未实现。
- 使用几十万的百度自动驾驶数据对CenterPoint进行了训练,提供了在城市道路场景效果更好的CenterPoint模型
3.指标说明
CenterPoint在nuScenes Val set数据集上的表现
Model | Voxel Format | mAP | NDS | V100 TensorRT FP32(FPS) | V100 TensorRT FP16(FPS) | Download | Log |
2D-Pillars | 50.97 | 61.30 | 50.28 | 63.43 | |||
3D-Voxels | 59.25 | 66.74 | 21.90 | 26.93 |
CenterPoint在KITTI Val set数据集上的表现
模型 | 体素格式 | 3DmAP Mod. | Car Easy Mod. Hard | Pedestrian Easy Mod. Hard | Cyclist Easy Mod. Hard | V100 TensorRT FP32(FPS) | V100 TensorRT FP16(FPS) | 模型下载 | 配置文件 | 日志 |
CenterPoint | 2D-Pillars | 64.75 | 85.99 76.69 73.62 | 57.66 54.03 49.75 | 84.30 63.52 59.47 | 43.96 | 74.21 | |||
模型 | 体素格式 | BEVmAP Mod. | Car Easy Mod. Hard | Pedestrian Easy Mod. Hard | Cyclist Easy Mod. Hard | V100 TensorRT FP32(FPS) | V100 TensorRT FP16(FPS) | 模型下载 | 配置文件 | 日志 |
CenterPoint | 2D-Pillars | 71.87 | 93.03 87.33 86.21 | 66.46 62.66 58.54 | 86.59 65.62 61.58 | 43.96 | 74.21 |
4.效果图
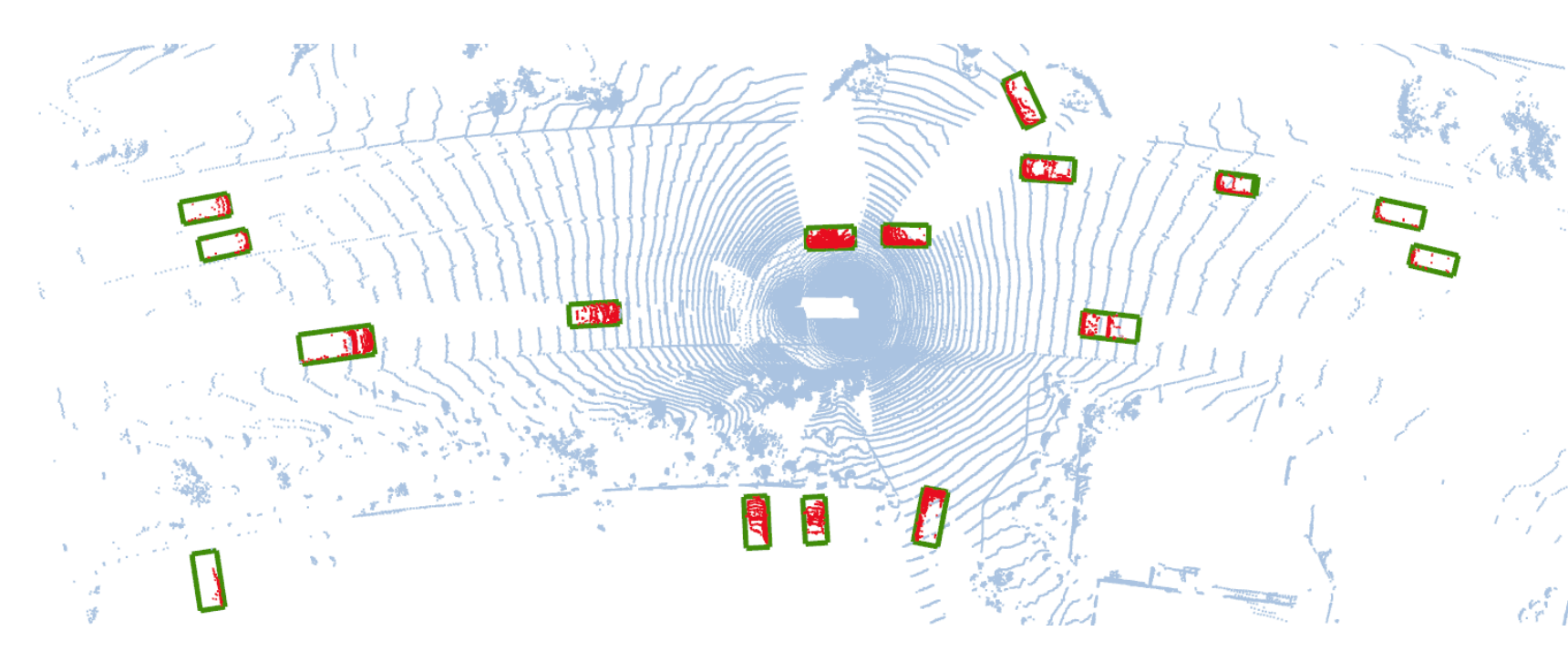
二、CenterPoint训练
centerpoint的完整训练流程可参考AI Studio项目:【自动驾驶实战】基于Paddle3D&Apollo的Lidar目标物检测-飞桨AI Studio星河社区
1.Paddle3D的安装
Paddle3D是飞桨官方开源的端到端深度学习3D感知套件,涵盖了许多前沿和经典的3D感知模型,支持多种模态和多种任务,可以助力开发者便捷地完成『自动驾驶』领域模型 从训练到部署的全流程应用。
代码库地址:https://github.com/PaddlePaddle/Paddle3D
Paddle3D安装教程:https://github.com/PaddlePaddle/Paddle3D/blob/develop/docs/installation.md
2.训练配置介绍
centerpoint的相关配置在https://github.com/PaddlePaddle/Paddle3D/tree/develop/configs/centerpoint中接下来将以centerpoint_pillars_016voxel_kitti.yml为例,介绍训练配置
3.基础配置
配置名称 | 默认值 | 含义 |
batch_size | 4 | 训练时一个batch包含的点云帧数 |
val_batch_size | 1 | 评测时一个batch包含的点云帧数 |
epochs | 160 | epoch个数 |
4.AMP配置 amp_cfg
自动混合精度(Automatic Mixed Precision,以下简称为 AMP)指的是在训练时使用fp16精度,提升计算速度并降低存储空间。详细介绍参考:https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/performance_improving/amp_cn.html
配置名称 | 默认值 | 含义 |
use_amp | False | 是否开启amp训练 |
enable | False | - |
level | O1 | 混合精度训练的策略,可选项:O1,O2 |
scalerinit_loss_scaling | 32.0 | 控制 loss 缩放比例,规避浮点数下溢问题 |
5.数据集配置 train_dataset / val_datasets
配置名称 | 默认值 | 含义 | ||
type | KittiPCDataset | 数据集类型 | ||
dataset_root | 数据集的路径 | datasets/KITTI | ||
transforms | LoadPointCloud | dim | 4 | 每个点的特征数,一般为x, y, z, intensity |
use_dim | 4 | 使用每个点的前use_dim个特征 | ||
RemoveCameraInvisiblePointsKITTI | - | 删除相机看不见区域的点云 | ||
SamplingDatabase | min_num_points_in_box_per_class | Car: 5Cyclist: 5Pedestrian: 5 | 每种类别的目标的最少点数 | |
max_num_samples_per_class | Car: 15Cyclist: 10 | 每帧点云中每种类别目标的最大个数 | ||
ignored_difficulty | [-1] | 困难程度限制 | ||
database_anno_path | datasets/KITTI/kitti_train_gt_database/anno_info_train.pkl | anno_info_train.pkl的路径 | ||
database_root | datasets/KITTI/ | 数据集的路径 | ||
class_names | ["Car", "Cyclist", "Pedestrian"] | 类别信息 | ||
RandomObjectPerturb | rotation_range | [-0.15707963267, 0.15707963267] | gt随机旋转的角度范围 | |
translation_std | [0.25, 0.25, 0.25] | gt随机平移的标准差 | ||
max_num_attempts | 100 | 最大候选数量 | ||
RandomVerticalFlip | - | 开启随机竖直翻转 | ||
GlobalRotate | min_rot | -0.78539816 | 全局旋转的最小旋转角 | |
max_rot | 0.78539816 | 全局旋转的最大旋转角 | ||
GlobalScale | min_scale | 0.95 | 全局缩放的最小缩放因子 | |
max_scale | 1.05 | 全局缩放的最大缩放因子 | ||
GlobalTranslate | translation_std | [0.2, 0.2, 0.2] | 全局平移的标准差 | |
ShufflePoint | - | 打乱点云的顺序 | ||
FilterBBoxOutsideRange | point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 过滤范围外的gt | |
Gt2CenterPointTarget | tasks | - num_class: 1class_names: ["Car"]- num_class: 2class_names: ["Cyclist", "Pedestrian"] | centerpoint的head设置 | |
down_ratio | 2 | 下采样倍率 | ||
point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 点云范围 | ||
voxel_size | [0.16, 0.16, 4] | voxel的尺寸 | ||
gaussian_overlap | 0.1 | 高斯重叠数值 | ||
max_objs | 500 | 一帧最多允许的gt数量 | ||
min_radius | 2 | 生成heatmap时每个gt的最小半径 | ||
mode | train | 训练模式 | ||
class_balanced_sampling | False | 开启类别采样 | ||
class_names | ["Car", "Cyclist", "Pedestrian"] | 类别信息 | ||
- SamplingDatabase
数据增强之前 | 数据增强之后 |
 |  |
6.优化器配置 optimizer
配置名称 | 默认值 | 含义 | |
type | OneCycleAdam | 优化器类型 | |
beta2 | 0.99 | beta2 | |
weight_decay | 0.01 | 衰减系数 | |
grad_clip | type | ClipGradByGlobalNorm | 梯度裁剪 |
clip_norm | 35 | ||
beta1 | type | OneCycleDecayWarmupMomentum | 动量设置 |
momentum_peak | 0.95 | ||
momentum_trough | 0.85 | ||
step_ratio_peak | 0.4 | ||
7.学习率设置 lr_scheduler
配置名称 | 默认值 | 含义 |
type | OneCycleWarmupDecayLr | 学习率类型 |
base_learning_rate | 0.001 | 初始学习率 |
lr_ratio_peak | 10 | 最大学习率的比例因子 |
lr_ratio_trough | 0.0001 | 最小学习率的比例因子 |
step_ratio_peak | 0.4 | 到达最大值的step比例 |
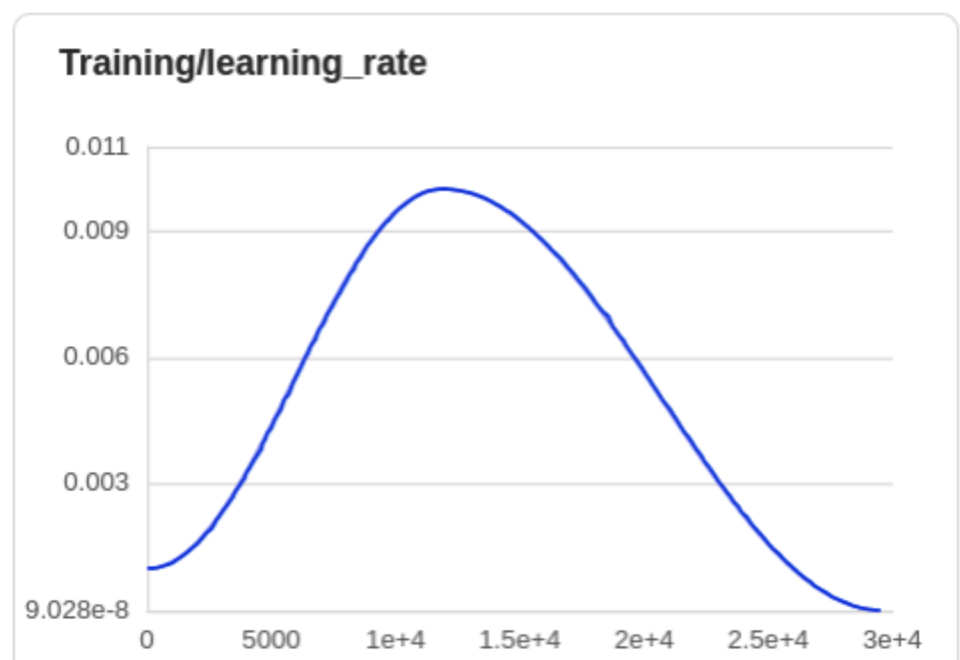
8.模型配置 model
配置名称 | 默认值 | 含义 | |
type | CenterPoint | 模型名称 | |
voxelizer | type | HardVoxelizer | 体素化方法 |
point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 点云范围 | |
voxel_size | [0.16, 0.16, 4] | voxel尺寸 | |
max_num_points_in_voxel | 100 | 每个voxel中最多的点数 | |
max_num_voxels | [12000, 40000] | 训练/推理时voxel数量 | |
voxel_encoder | type | PillarFeatureNet | voxel_encoder名称 |
in_channels | 4 | 输入的channel数量 | |
feat_channels | [64, 64] | fc层的输出channel | |
with_distance | False | 是否使用distance特征 | |
max_num_points_in_voxel | 100 | 每个voxel中最多的点数 | |
voxel_size | [0.16, 0.16, 4] | voxel尺寸 | |
point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 点云范围 | |
middle_encoder | type | PointPillarsScatter | middle_encoder名称 |
in_channels | 64 | 输入channel数量 | |
voxel_size | [0.16, 0.16, 4] | voxel尺寸 | |
point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 点云范围 | |
backbone | type | SecondBackbone | backbone名称 |
in_channels | 64 | 输入channel | |
out_channels | [64, 128, 256] | 每个stage的输出channel | |
layer_nums | [3, 5, 5] | 每个stage的卷积层个数 | |
downsample_strides | [1, 2, 2] | 每个stage的降采样步长 | |
neck | type | SecondFPN | neck名称 |
in_channels | [64, 128, 256] | 输入channel | |
out_channels | [128, 128, 128] | 输出channel | |
upsample_strides | [0.5, 1, 2] | 上采样步长 | |
use_conv_for_no_stride | True | 是否在未上采样处使用卷积层 | |
bbox_head | type | CenterHead | head名称 |
in_channels | 384 | 输入channel | |
tasks | - num_class: 1class_names: ["Car"]- num_class: 2class_names: ["Cyclist", "Pedestrian"] | head设置 | |
weight | 0.25 | 定位损失的权重 | |
code_weights | [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0] | 8种定位属性的权重 | |
common_heads | reg: [2, 2]height: [1, 2]dim: [3, 2]rot: [2, 2] | 4种head的设置 | |
test_cfg | post_center_limit_range | [-10., -50., -10., 80., 50., 10.] | dt center的范围 |
nms_pre_max_size | 1000 | nms之前的dt数量 | |
nms_post_max_size | 83 | nms之后的dt数量 | |
nms_iou_threshold | 0.1 | nms iou阈值 | |
score_threshold | 0.1 | 置信度阈值 | |
point_cloud_range | [0, -39.68, -3, 69.12, 39.68, 1] | 点云范围 | |
down_ratio | 2 | 下采样倍率 | |
voxel_size | [0.16, 0.16, 4] | voxel尺寸 | |
9.训练流程介绍
1)数据准备
接下来以KITTI数据集为例,训练CenterPoint模型
- Download Velodyne point clouds, if you want to use laser information (29 GB)
- training labels of object data set (5 MB)
- camera calibration matrices of object data set (16 MB)
- 并下载数据集的划分文件列表:
- 将数据解压后按照下方的目录结构进行组织:
- 在Paddle3D的目录下创建软链接
datasets/KITTI,指向到上面的数据集目录:
- 生成训练时数据增强所需的真值库:
--dataset_root指定KITTI数据集所在路径,--save_dir指定用于保存所生成的真值库的路径。该命令执行后,save_dir生成的目录如下:
注:如果想用自己的数据集进行训练,推荐将自己的数据集组织为KITTI标准格式。
2)训练
KITTI数据集上的训练使用8张GPU:
训练启动参数介绍:
参数名 | 用途 | 是否必选项 | 默认值 |
iters | 训练迭代步数 | 否 | 配置文件中指定值 |
epochs | 训练迭代次数 | 否 | 配置文件中指定值 |
batch_size | 单卡batch size | 否 | 配置文件中指定值 |
learning_rate | 初始学习率 | 否 | 配置文件中指定值 |
config | 配置文件路径 | 是 | - |
save_dir | 检查点(模型和visualdl日志文件)的保存根路径 | 否 | output |
num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 2 |
save_interval | 模型保存的间隔步数 | 否 | 1000 |
do_eval | 是否在保存模型时启动评估 | 否 | 否 |
log_interval | 打印日志的间隔步数 | 否 | 10 |
resume | 是否从检查点中恢复训练状态 | 否 | None |
keep_checkpoint_max | 最多保存模型的数量 | 否 | 5 |
quant_config | 量化配置文件,一般放在configs/quant目录下 | 否 | None |
seed | Paddle/numpy/random的全局随机种子值 | 否 | None |
model | 基于预训练模型进行finetune | 否 | .pdparam模型文件 |
3)评估
注意:CenterPoint的评估目前只支持batch_size为1。评估启动参数介绍如下所示:
参数名 | 用途 | 是否必选项 | 默认值 |
batch_size | 单卡batch size | 否 | 配置文件中指定值 |
config | 配置文件路径 | 是 | - |
model | 模型参数文件的路径 | 是 | - |
num_workers | 用于异步读取数据的进程数量, 大于等于1时开启子进程读取数据 | 否 | 2 |
quant_config | 量化配置文件,一般放在configs/quant目录下 | 否 | None |
4)训练过程可视化
Paddle3D使用VisualDL来记录训练过程中的指标和数据,我们可以在训练过程中,在命令行使用VisualDL启动一个server,并在浏览器查看相应的数据
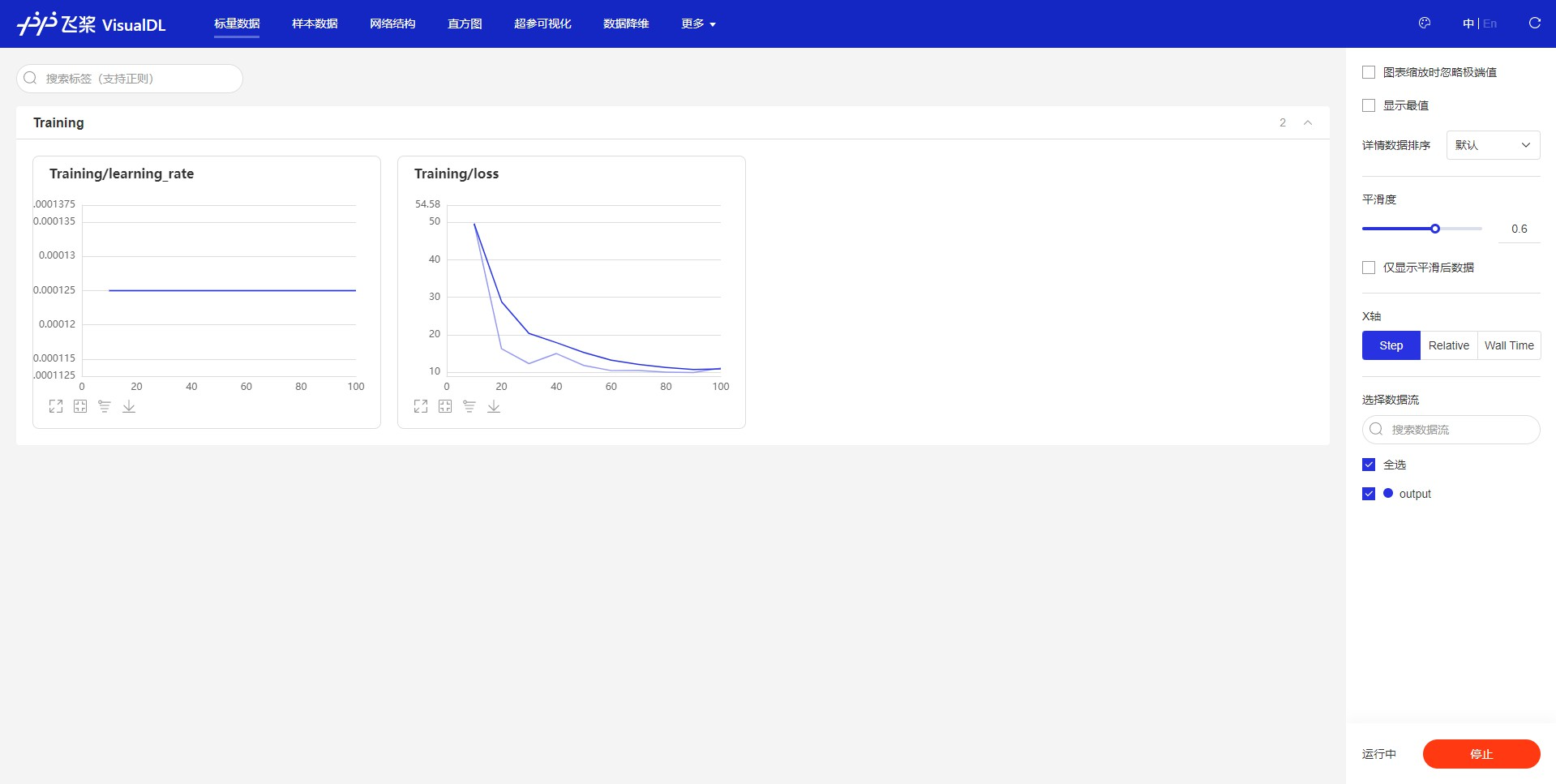
5)导出模型介绍
运行以下命令,将训练时保存的动态图模型文件导出成推理引擎能够加载的静态图模型文件。
导出脚本参数介绍
参数名 | 用途 | 是否必选项 | 默认值 |
config | 配置文件路径 | 是 | - |
model | 模型参数路径 | 否 | - |
export_for_apollo | 是否用于Apollo部署,当打开该开关时,会同步生成用于Apollo部署的meta文件 | 否 | False |
save_dir | 推理模型文件的保存路径 | 否 | exported_model |
save_name | 推理模型文件的保存名字 | 否 | None(由各模型自定决定) |
quant_config | 量化配置文件,一般放在configs/quant目录下,如果模型使用量化训练,则在模型导出时同样需要指定量化配置文件 | 否 |
运行完成之后,会输出如下的文件
三、部署CenterPoint到Apollo中
接下来介绍如何将导出的centerpoint模型部署到apollo中,使用centerpoint模型进行3d目标检测
1.CenterPoint部署配置
首先介绍一下centerpoint部署的配置,配置文件路径:/apollo/modules/perception/lidar_detection/data/center_point_param.pb.txt
ModelInfo配置,文件路径:modules/perception/common/proto/model_info.proto
参数类型 | 参数名 | 默认值 | 含义 |
string | name | / | 模型名称,同models/下文件夹名 |
string | framework | / | 模型推理框架 |
string | ModelFile.proto_file | / | 模型网络结构 |
string | ModelFile.weight_file | / | 模型权重文件 |
string | ModelFile.anchors_file | / | anchor size |
string | ModelBlob.inputs | / | 模型输入数据名称及维度 |
int32 | ModelBlob.outputs | / | 模型输出数据名称及维度 |
PointCloudPreProcess:
参数类型 | 参数名 | 默认值 | 含义 |
int32 | gpu_id | 0 | GPU的id |
double | normalizing_factor | 255 | 强度归一化的缩放因子 |
int32 | num_point_feature | 4 | 每个点的特征数量 |
bool | enable_ground_removal | false | 是否过滤掉地面点 |
double | ground_removal_height | -1.5 | 过滤掉z值小于阈值的点 |
bool | enable_downsample_beams | false | 是否根据beam id对点云进行过滤 |
int32 | downsample_beams_factor | 4 | 保留beam id为downsample_beams_factor的倍数的点云 |
bool | enable_downsample_pointcloud | false | 是否根据voxel过滤点云 |
double | downsample_voxel_size_x | 0.01 | 过滤时voxel的x方向长度 |
double | downsample_voxel_size_y | 0.01 | 过滤时voxel的y方向长度 |
double | downsample_voxel_size_z | 0.01 | 过滤时voxel的z方向长度 |
bool | enable_fuse_frames | false | 是否融合多帧点云 |
int32 | num_fuse_frames | 5 | 融合点云的帧数 |
double | fuse_time_interval | 0.5 | 融合点云的时间间隔 |
bool | enable_shuffle_points | false | 是否打乱点云索引 |
int32 | max_num_points | 2147483647 | 允许的最大点云数量 |
bool | reproduce_result_mode | false | 是否开启复现结果模式 |
bool | enable_roi_outside_removal | false | 是否在输入模型之前将roi外的点云进行过滤 |
PointCloudPostProcess
参数类型 | 参数名 | 默认值 | 含义 |
float | score_threshold | 0.5 | 置信度阈值 |
float | nms_overlap_threshold | 0.5 | NMS的iou阈值 |
int32 | num_output_box_feature | 7 | 输出障碍物的属性个数 |
float | bottom_enlarge_height | 0.25 | 获取目标真实点云时向上扩充的范围 |
float | top_enlarge_height | 0.25 | 获取目标真实点云时向下扩充的范围 |
float | width_enlarge_value | 0 | 获取目标真实点云时宽度扩充的范围 |
float | length_enlarge_value | 0 | 获取目标真实点云时长度扩充的范围 |
centerpoint独有的配置
参数类型 | 参数名 | 默认值 | 含义 |
ModelInfo | info | / | 模型通用配置 |
PointCloudPreProcess | preprocess | / | 预处理 |
PointCloudPostProcess | postprocess | / | 后处理 |
int32 | point2box_max_num | 5 | 每个点最多可以属于多少个box |
float | quantize | 0.2 | 将尺寸量化为quantize的倍数 |
2.部署apollo并查看效果
apollo的环境搭建:https://apollo.baidu.com/community/article/1133
进入Docker环境
上述步骤部署的是apollo官方的centerpoint模型,如果要部署自己的centerpoint模型,需要将上一步中导出的文件放置到/apollo/modules/perception/data/models/center_point_paddle下面即可
4.启动Dreamview
aem bootstrap start --plus
5.启动lidar感知程序
选择相应车型配置
启动transform模块
启动lidar感知模块
6.下载并播放感知包
方式一:在dreamview左下角点击resource manger,下载sensorrgb数据包,下载完成后选择sensorrgb数据包点击播放。


方式二:终端启动下载好的sensor_rgb数据包,下载链接参考开放资源record下载。
cyber_recorder play -f sensor_rgb.record
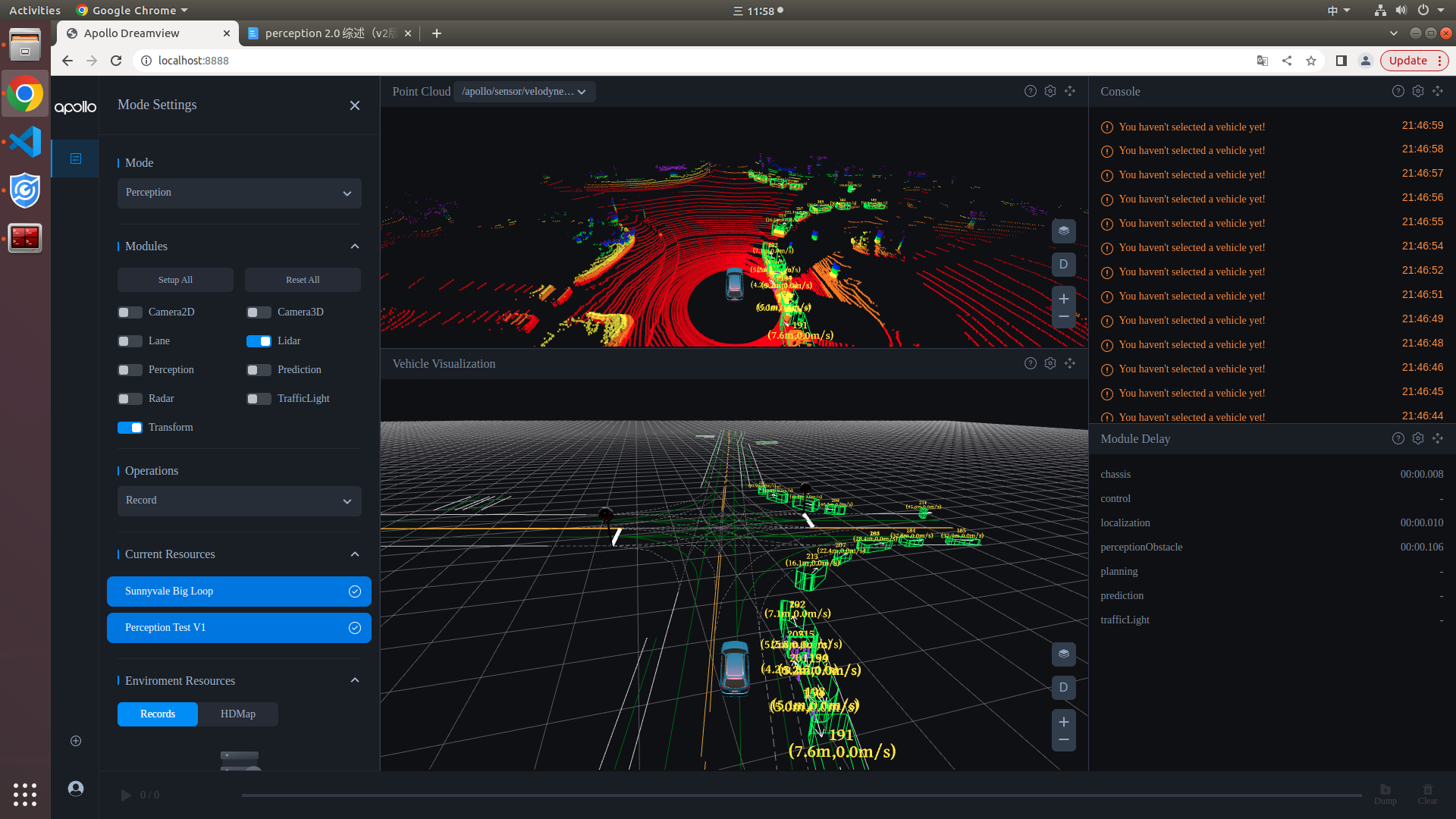
dreamview查看lidar检测结果
7.注意事项
1)如何使用自己训练的模型进行推理
- 使用amodel安装的centerpoint是使用百度自动驾驶数据训练的预训练模型
- 如果想要使用自己训练的模型进行推理,只需要将导出的.zip文件放到/apollo_workspace路径下,使用amodel安装即可
2)自己训练的模型部署到apollo后没有输出结果
- 现象描述:部署了自己训练的模型之后,在dreamview上看不到障碍物
- 问题原因:没有修改模型的output_names
- 解决方法
- 使用visualdl命令查看导出的.pdmodel文件,查看最终输出的名称


- 在/apollo/modules/perception/lidar_detection/data/center_point_param.pb.txt中修改
